MF KESSAI開発合宿運営(CTO)の@shinofaraです。 前回に引き続き、チーム対抗パフォーマンス改善合宿の様子をお送りします。
今回は仕組み編です。チームで競い合えるような仕組みをどのようにしてつくっていったかをお伝えします。
チーム対抗の課題
タイトルの通り、今回の合宿はチームごとにパフォーマンス改善を競い合う内容としました。そのためには各チームが行ったパフォーマンス改善の効果を測定し、チーム間で比較できるようにする指標が必要です。
また、リモートでの開催であったため、各チームの改善状況がすぐに分かるように継可視化の仕組みもほしいところです。
これらをある程度自動化して合宿当日はスムーズに取り組めるようにすることが課題でした。目標は当日に運営として何もしない!です。
パフォーマンス計測の実行環境
今回、パフォーマンス計測のためGKE上に本番と同じ構成のテスト環境を作成しました。
本当はチームごとのエンドポイントを実現したかったのですが、今回は同じDeploymentに対して各チームが作成したイメージのPatchを当てて順番に仲良く使う形としました。 当初はそこまでデプロイタイミングはかぶらないだろうと思っていたのですが、実際には細かい改善サイクルを何度も繰り返していたのでデプロイ順番待ちが発生してしまいました。
デプロイ方法
パフォーマンス計測のトリガーとしてGitHub Actionsのworkflow_dispatchを利用しました。
workflow_dispatchを使うことでUI上から任意の値を入力でき、その値をステップ中で利用できます。
各チームで作成したイメージのタグを入力値として指定して、前述のテスト環境にapplyする以下のようなジョブを定義しました。
on:
workflow_dispatch:
inputs:
hoge_image_tag:
description: 'hoge image tag'
required: true
default: 'latest'
jobs:
invoke:
steps:
- name: Deploy
run: |-
kubectl set image deployment.v1.apps/$DEPLOYMENT_NAME hoge=gcr.io/<YOUR GCP PROJECT>/hoge:${{ github.event.inputs.hoge_image_tag }} -n namespace
kubectl rollout status deployment/$DEPLOYMENT_NAME -n namespace負荷をかける
デプロイされたらパフォーマンス計測のためにある程度の負荷をかけます。こちらもGitHub Actionsのステップとしてデプロイ後に実行されます。
負荷テストツールとしてはNordstrom/serverless-artilleryを使用しました。
実行内容としては一定時間かけて徐々にリクエスト数を増やしていったあと、さらに一定時間高い負荷をかけ続けるものです。 ほとんどArtilleryのドキュメントにある例と同じような感じです。
可視化
負荷テストの結果を可視化にはData Studioを利用しました。
Artilleryの実行結果をJSON出力し、それをBigQueryに溜めていく以下のようなステップを作成しました。
- name: Load to BigQuery
run: |
cd scenarios/
cat result.json | jq -c "." | head -1 | jq . > a.json
cat a.json | jq '. |= .+ {"team": "${{ github.event.inputs.team }}"}' > b.json
cat b.json | jq '.codes["_403"] = (.codes["403"]+0) | .codes["_400"] = (.codes["400"]+0) | .codes["_200"] = (.codes["200"]+0) | .codes["_500"] = (.codes["500"]+0) | .codes["_502"] = (.codes["502"]+0) | del(.codes["403"], .codes["500"], .codes["200"], .codes["400"], .codes["502"], .customStats, .errors, .phases)' > c.json
cat c.json| jq -c "" > f.json
bq load \
--project_id=your-gcp-project \
--autodetect \
--source_format=NEWLINE_DELIMITED_JSON \
dataset.table \
./f.jsonちょっとごちゃごちゃしていますが、BigQueryに数字始まりのカラム名を作れないので、適当なprefixをつけたりする加工をしています。
こうして溜め込んだデータをData Studioで可視化すると以下のようなグラフが作れます。
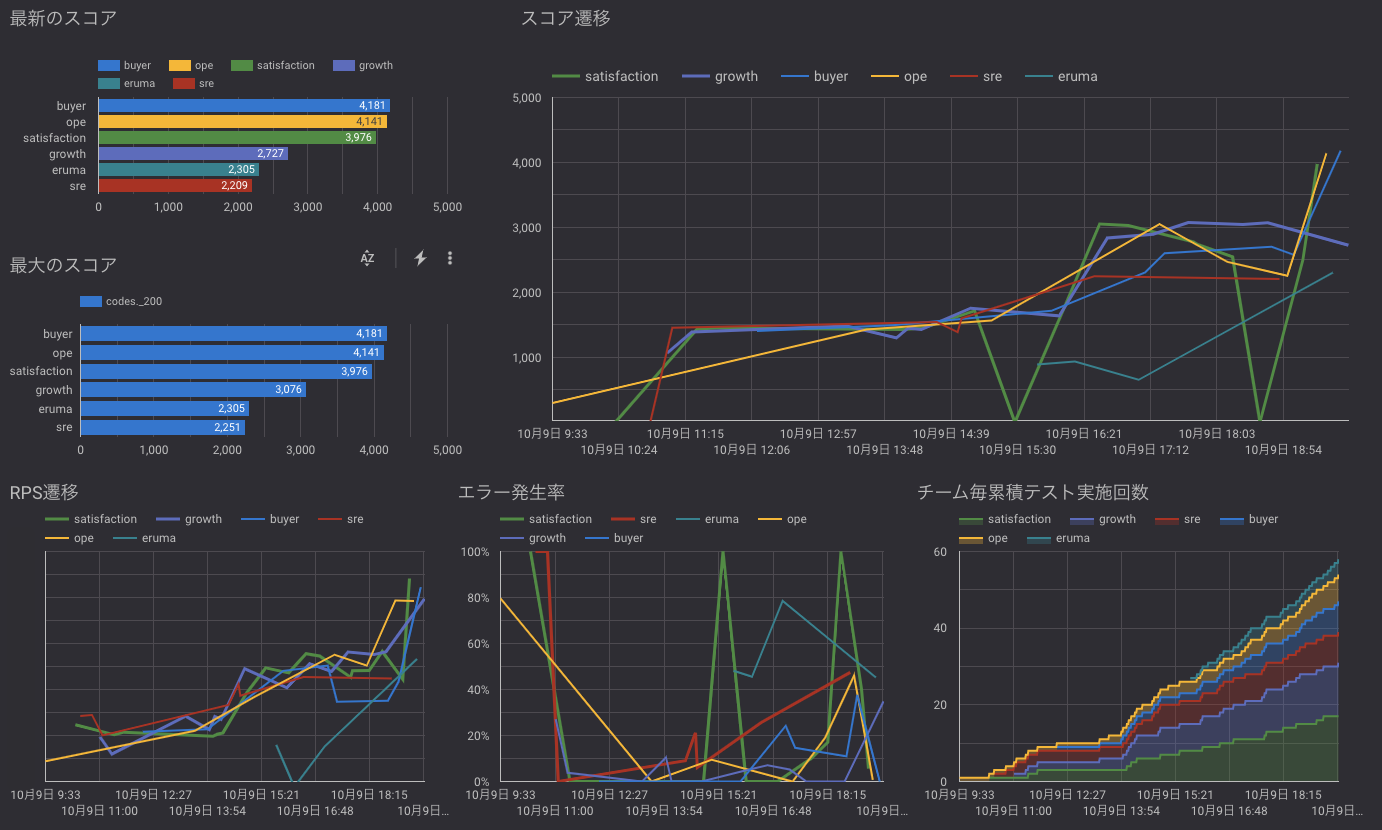
チームごとの成績の推移になっていて、これを見ながら各チーム競い合って改善をすすめていきました。
まとめ
Google Cloudの各種サービスやGitHub Actionsなど便利なサービスがいろいろあったおかげで、比較的少ない手間で仕組みを作れたかなと思っています。
実際にこれらの仕組みを用意したことで、合宿当日はスムーズにパフォーマンス改善に取り組めました。
合宿のような短期的なパフォーマンス改善の取り組みだけでなく、継続的なパフォーマンス計測にも使えるかと思うので、ぜひ参考にしてみてください。